Zerynth Docs
The Zerynth Industrial IoT & AI Platform Guide
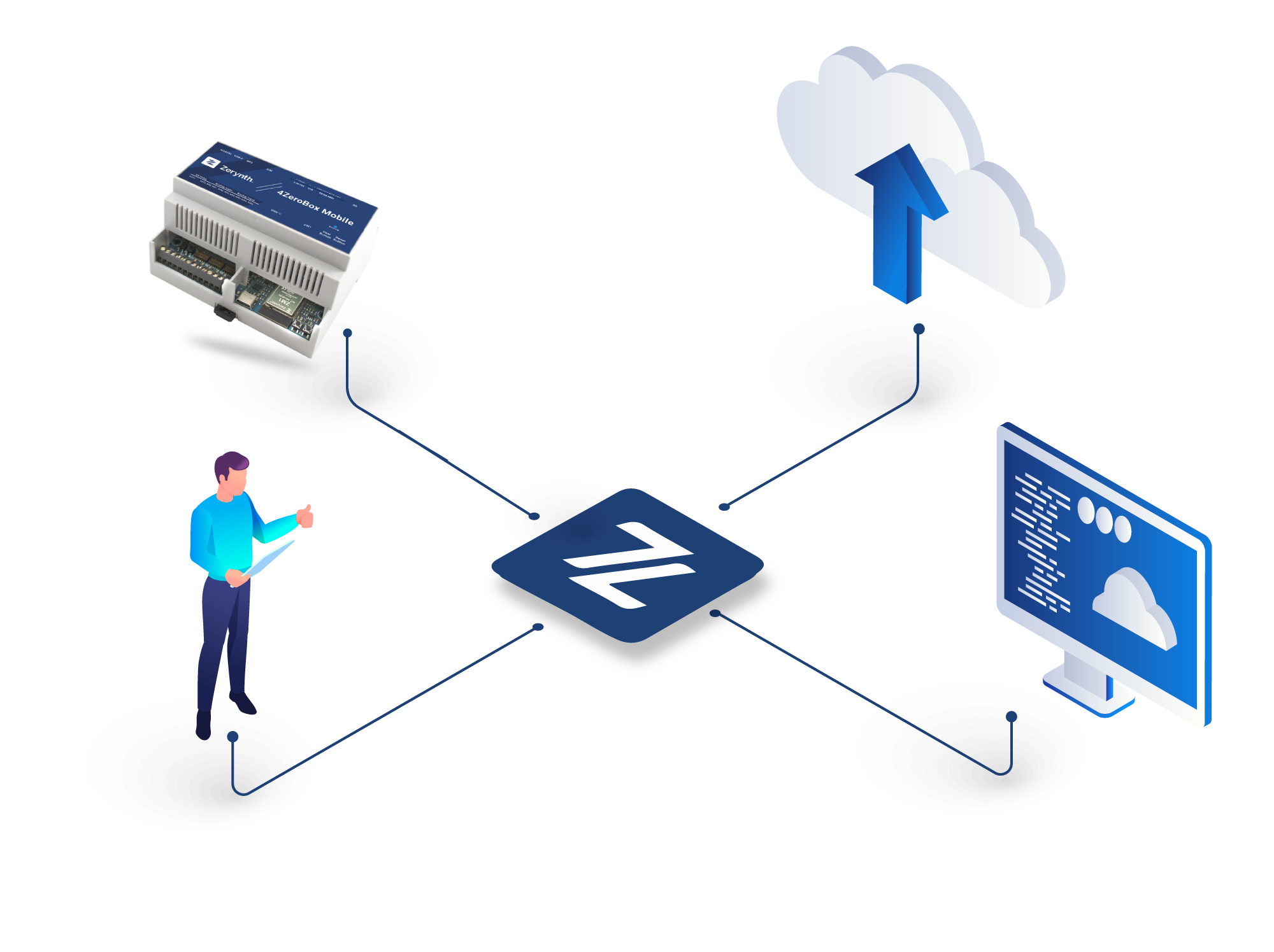
We are thrilled to present the Zerynth Industrial IoT & AI Platform guide, tailored specifically for our customers and partners engaged in factory digitization. This guide is meticulously crafted to address the needs of those focusing on the digital transformation of manufacturing processes.
Zerynth enables companies to streamline production processes and increase the value of connected industrial products. Through a plug-and-play IoT & AI platform, we connect any industrial machine, allowing for a complete 4.0 transformation quickly, flexibly, and securely.